
12月27日,外洋酬酢媒体平台X被来自中国的大模子DeepSeek-V3刷屏了,科技圈感叹的点在于,这一模子才能对标头部模子,但查考的预算却相配低,“2048个GPU、2个月、近600万好意思元”,比较之下,GPT-4o等模子的查考资本约为1亿好意思元,至少在万个GPU量级的规划集群上查考。
“Llama 3 405B 使用了3080万GPU小时,而DeepSeek-V3 看起来是一个更遒劲的模子,仅使用了280万GPU 小时(规划量约为十分之一)。”前Open AI 谐和创举东谈主、Tesla AI 团队负责东谈主Andrej Karpathy在X上发文示意,若是该模子的优良表露约略得到粗鄙考据,这一模子将是在资源受限的情况下,在推断和工程方面让东谈主印象深刻的一次展示。
12月26日晚,幻方量化旗下AI公司深度求索(DeepSeek)文书,全新系列模子DeepSeek-V3上线并同步开源,API工作已同步更新,接口设立无需转换,登录官网(chat.deepseek.com)即可与最新版 V3 模子对话。面前版块的 DeepSeek-V3 暂不辅助多模态输入输出。
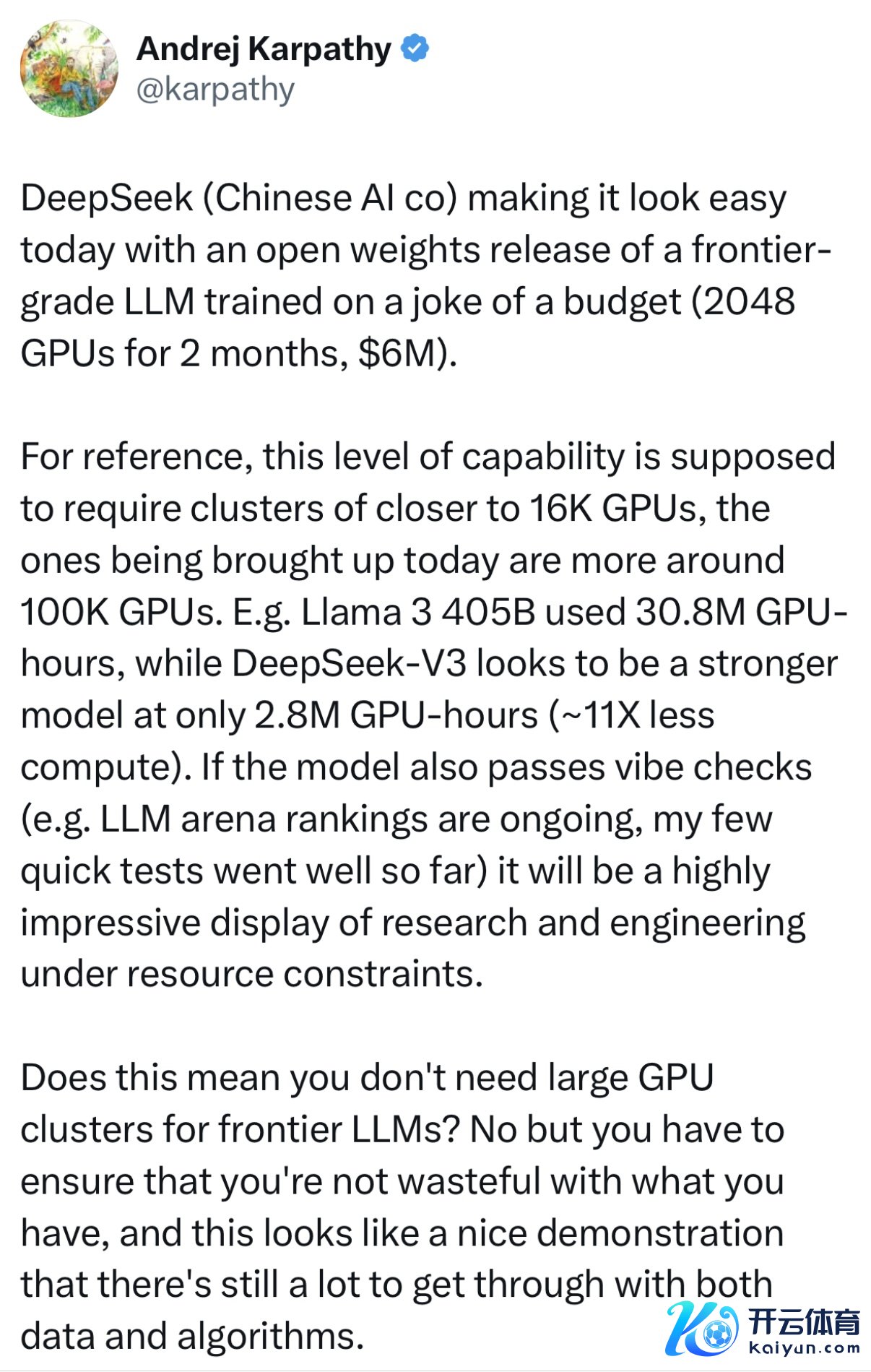
具体来说,DeepSeek-V3是一个具有6710亿总参数的MoE(羼杂大众)模子,每token激活参数为370亿,在14.8万亿token上进行了预查考。
官方给出的数据线路,DeepSeek-V3 多项评测获利越过了阿里通义的 Qwen2.5-72B 和Meta的Llama-3.1-405B 等其他开源模子,并在性能上和宇宙顶尖的闭源模子 GPT-4o 以及 Claude-3.5-Sonnet 不分昆季。
与此同期,DeepSeek示意,通过算法和工程上的转换,DeepSeek-V3 的生成吐字速率提高了三倍,从20 TPS提高至60 TPS,API工作价钱也同步作念了调理,现在为每百万输入tokens 0.5元(缓存射中)/2元(缓存未射中),每百万输出tokens 8元。但全新模子有45天的优惠价钱体验期,为每百万输入tokens 0.1元(缓存射中)/1元(缓存未射中),每百万输出tokens 2元。
这一价钱在现在头部模子阛阓中有一定的竞争力。举例OpenAI的GPT 4o订价为输入:5好意思元/百万Token,输出:15好意思元/百万Token,加总资本是20好意思元,约合东谈主民币145元。
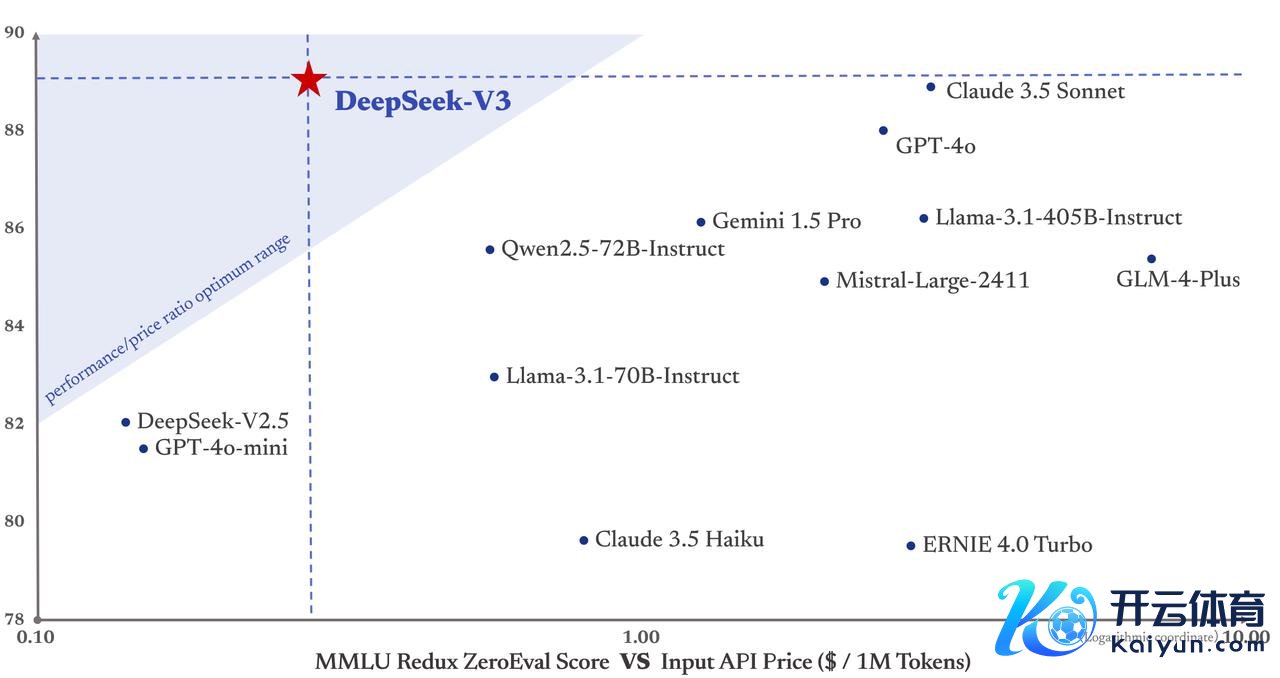
DeepSeek此前一直走的是性价比路子,在查考上作念了一些调理。据这次发布的技能陈诉,DeepSeek-V3仍然采纳多头潜在严防力(MLA)以完了高效推理,并采纳 DeepSeek MoE以完了经济的查考。这两种架构在 DeepSeek-V2中得到了考据,解说了它们在保握遒劲模子性能的同期,约略完了高效的查考和推理。
除了基本架构外,DeepSeek还实行了两项很是策略以进一步增强模子才能。当先是采纳了无辅助蚀本的负载均衡策略,其次采纳了多token预计查考方针,这不错普及评估基准的举座性能。
在已开源的论文中,DeepSeek强调了其查考资本较低——通过对算法、框架和硬件的优化协同联想,在预查考阶段,模子每查考1万亿token仅需要18万个GPU小时,即在团队配备2048个H800 GPU的集群上只需3.7天,也即是说,团队的预查考在不到2个月的时辰内完成。

此外,加上用于膨大高下文长度所需的11.9万个 GPU小时和5000个 GPU小时的后查考,DeepSeek-V3完好查考消耗了278.8万个GPU小时。
假定H800 GPU的租用价钱为每块GPU 2好意思元/小时,DeepSeek-V3的一王人查考资本合计仅为557.6万好意思元。DeepSeek示意,该资本仅包括DeepSeek-V3的崇敬查考,不包括与先前在架构、算法或数据上的推断和消融实验相干的资本。
Karpathy在发文中细则了这一查考资本的冲突,他提到,算作参考,要达到V3这种级别的才能,频繁需要约1.6万个GPU的规划集群。不仅如斯,面前业界正在部署的集群规模致使还是达到了10万个GPU。
但这是否意味着前沿LLM不需要大型 GPU 集群?在Karpathy看来,也并非如斯,“但你必须确保不奢侈你所领有的资源,这看起来是一个很好的解说,标明在数据和算法方面还有许多使命要作念” 。
Karpathy同期夸赞了DeepSeek在开源网站上公布的技能陈诉,“这瑕瑜常好且详备的技能陈诉,值得一读。”一位来自Menlo Venture的投资东谈主也欷歔,“53 页的技能论文是黄金”(53-page technical paper is GOLD)。
英伟达高等推断科学家Jim Fan在X上转发Karpathy的推文示意,资源甩掉是一件好意思好的事情。在清高的东谈主工智能竞争环境中,生涯本能是取得冲突的主要能源。“我关怀 DeepSeek 很深刻。旧年他们推出了最好的开源模子之一,稀奇的OSS模子给买卖前沿 LLM 公司带来了弘远压力,迫使它们加速方法。”
Lepton AI 创举东谈主、 前阿里巴巴副总裁贾扬清也参与了这一话题的询查,他以为,DeepSeek 的到手是浅陋的奢睿和实用宗旨在起作用,在规划和东谈主力有限的情况下,通过智能推断产生最好后果。
此前DeepSeek一直被冠以“AI界拼多多”的名头,亦然年中激发中国大模子价钱战的泉源。本年5月,DeepSeek发布的一款名为DeepSeek V2的开源模子,提供了一种史无先例的性价比:推理资本被降到每百万token仅 1块钱,在那时约等于Llama3 70B的七分之一,GPT-4 Turbo的七十分之一。随后,字节、腾讯、百度、阿里等大厂纷纷降价,大模子价钱战由此一触即发。
公开信息线路,DeepSeek成立于2023年7月,由知名量化资管巨头幻方量化创立,幻方量化创举东谈主梁文峰在量化投资和高性能规划领域具有深厚的配景和丰富的教育。
在这次DeepSeek-V3发布时,大模子生态社区OpenCSG(绽开逼真)创举东谈主陈冉第一时辰关怀到的是查考数据,他对第一财经示意,“一切都是数据,数据质地决定模子质地”,Deepseek-V3基于14万亿token的数据查考,这些数据应该相配有价值。
举报 第一财经告白衔尾,请点击这里此执行为第一财经原创,文章权归第一财经总计。未经第一财经籍面授权,不得以任何模式加以使用,包括转载、摘编、复制或确立镜像。第一财经保留精致侵权者法律牵涉的权柄。 如需赢得授权请相干第一财经版权部:021-22002972或021-22002335;banquan@yicai.com。 文章作家
刘晓洁
相干阅读 一个自闭症孩子的父亲,思用大模子为孩子治病
一个自闭症孩子的父亲,思用大模子为孩子治病自闭症调养有一个尽头杰出的痛点,它莫得药物,一王人都要靠东谈主工侵略。而自闭症的数字疗法主要即是作念两件事,一是重构客不雅宇宙,二是重构酬酢场景。
105 昨天 09:39 开源鸿蒙5.0发布,底座及配套才能走向褂讪训诲
开源鸿蒙5.0发布,底座及配套才能走向褂讪训诲现在,以开源鸿蒙为底座的生态开采数目冲突10亿。
135 12-21 11:35 10月工业利润降幅大幅收窄,降资本仍需战术加力
10月工业利润降幅大幅收窄,降资本仍需战术加力10月制造业利润降幅较9月大幅收窄22.3个百分点,带动规上工业利润降幅较9月收窄17.8个百分点。
467 11-27 20:58 李彦宏说大模子幻觉基本根除了,实测文心一言到底如何样?
李彦宏说大模子幻觉基本根除了,实测文心一言到底如何样?给AI文生图打几分?
766 11-13 12:28 固态电板量产时辰表出炉,新能源汽车迎来技能校阅
固态电板量产时辰表出炉,新能源汽车迎来技能校阅总计这个词产业正朝着2027年操纵上车、2030年完了大规模产业化的方针野心全固态电板的买卖化进度开云(中国)kaiyun网页版登录入口,2026-2028年有望成为国产新能源汽车全固态电板搭载谐和上市窗口。
303 11-12 20:08 一财最热 点击关闭